

No artigo anterior desta série, exploramos um dos riscos mais emergentes da inteligência artificial moderna: o prompt injection.
Vimos que esse tipo de ataque tenta manipular modelos de linguagem por meio de instruções maliciosas inseridas em texto, documentos ou conteúdos analisados por sistemas de IA. Em muitos casos, essas instruções tentam persuadir o modelo a ignorar suas regras originais ou executar ações que não deveria.
Quando modelos de linguagem operam apenas como interfaces de conversa, o impacto desse tipo de ataque tende a ser limitado.
No entanto, o cenário muda radicalmente quando esses modelos passam a atuar como agentes de IA.
Agentes de inteligência artificial podem:
- acessar bancos de dados
- consultar APIs externas
- executar automações
- interagir com sistemas corporativos
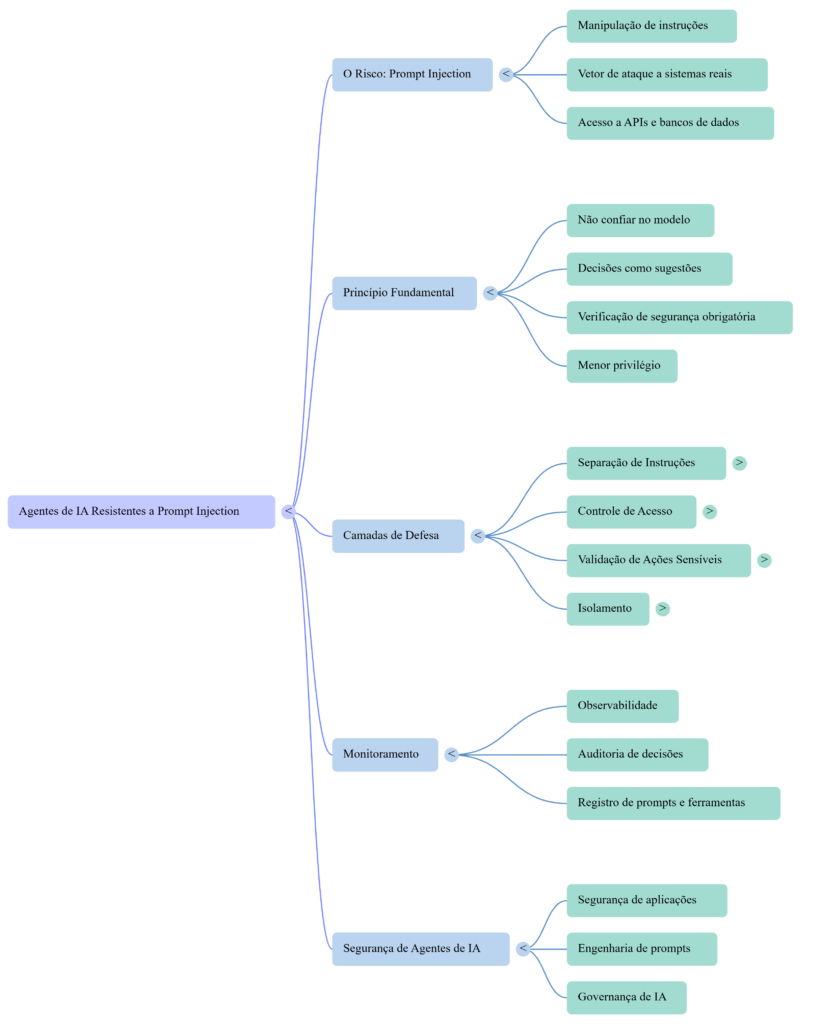
Nesse contexto, um prompt malicioso não é apenas uma tentativa de manipular uma resposta textual. Ele pode se tornar um vetor de ataque contra sistemas reais.
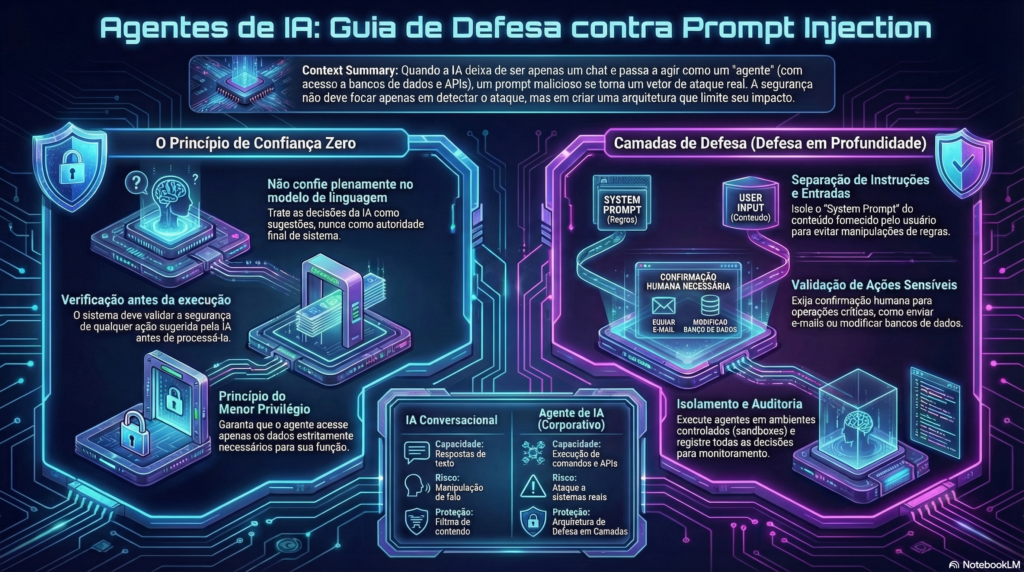
Por essa razão, a segurança de agentes de IA não pode depender apenas da capacidade de detectar prompts maliciosos. Em vez disso, é necessário projetar arquiteturas capazes de limitar o impacto de possíveis manipulações.
O princípio fundamental: não confiar no modelo
Uma das ideias mais importantes que emergiram no campo da segurança de IA é relativamente simples:
não confie completamente no modelo de linguagem.
Modelos de linguagem são excelentes para interpretar texto, gerar respostas e sintetizar informações. No entanto, eles não foram projetados para atuar como mecanismos confiáveis de controle de segurança.
Isso significa que sistemas baseados em agentes precisam tratar as decisões do modelo como sugestões, e não como autoridade final.
Em outras palavras:
o modelo pode sugerir uma ação, mas o sistema precisa verificar se essa ação é segura antes de executá-la.
Esse princípio se aproxima muito de conceitos tradicionais da segurança da informação, como:
- princípio do menor privilégio
- validação de entrada
- separação de responsabilidades
Camadas de defesa para agentes de IA
Para reduzir os riscos associados ao prompt injection, especialistas têm defendido uma abordagem baseada em defesa em profundidade.
Isso significa que a segurança não deve depender de um único mecanismo de proteção, mas sim de múltiplas camadas complementares.
Entre as principais camadas de defesa para agentes de IA, destacam-se:
1. Separação entre instruções do sistema e entrada do usuário
Uma das primeiras medidas de segurança consiste em separar claramente:
- instruções do sistema (system prompts)
- conteúdo fornecido pelo usuário ou por fontes externas
Essa separação ajuda a reduzir o risco de que instruções maliciosas sejam interpretadas como regras do sistema.
2. Controle de acesso a ferramentas
Agentes de IA frequentemente possuem acesso a diferentes ferramentas e serviços.
Essas ferramentas podem incluir:
- consultas a bancos de dados
- acesso a APIs
- execução de scripts
- automações de workflow
Um princípio essencial é garantir que o agente não tenha acesso irrestrito a essas capacidades.
Cada ação deve passar por mecanismos de controle que validem:
- se a operação é permitida
- se o contexto é legítimo
- se o usuário possui autorização para aquela ação
3. Validação de ações sensíveis
Algumas operações realizadas por agentes de IA podem ter impacto direto em sistemas corporativos.
Exemplos incluem:
- modificar dados
- enviar e-mails
- executar comandos administrativos
- acessar informações confidenciais
Para essas situações, é recomendável implementar mecanismos de validação adicional, como:
- confirmação humana
- políticas de autorização
- regras de negócio explícitas
4. Isolamento de execução
Outra prática importante consiste em executar agentes de IA em ambientes controlados.
Isso pode incluir:
- sandboxes
- ambientes isolados
- limites de acesso a arquivos e rede
Esse tipo de isolamento ajuda a reduzir o impacto caso o agente seja manipulado por um prompt malicioso.
5. Observabilidade e auditoria
Por fim, sistemas baseados em agentes precisam oferecer visibilidade sobre suas decisões.
Isso significa registrar informações como:
- prompts recebidos
- decisões tomadas pelo agente
- ferramentas acionadas
- resultados das ações executadas
Esses registros são fundamentais para:
- investigar incidentes
- melhorar os mecanismos de defesa
- compreender como o sistema está sendo utilizado
Uma nova disciplina dentro da segurança da informação
À medida que agentes de inteligência artificial começam a se integrar a sistemas corporativos, um novo campo começa a emergir dentro da segurança da informação.
Esse campo pode ser descrito como segurança de agentes de IA.
Ele combina elementos de diferentes áreas:
- segurança de aplicações
- segurança de APIs
- engenharia de prompts
- governança de inteligência artificial
Empresas que estão adotando agentes de IA em produção precisarão desenvolver novas práticas para lidar com esses desafios.
O próximo desafio: entender a superfície de ataque da IA
Projetar agentes de IA seguros é apenas uma parte do desafio.
Para proteger adequadamente esses sistemas, também é necessário compreender onde os ataques podem ocorrer.
Assim como aplicações tradicionais possuem superfícies de ataque bem definidas — como interfaces web, APIs e bancos de dados — sistemas baseados em agentes também apresentam diferentes pontos de exposição.
No próximo artigo desta série, vamos explorar exatamente esse tema.
Vamos analisar o mapa da superfície de ataque de agentes de IA, identificando os principais pontos onde ataques podem ocorrer e quais mecanismos podem ser usados para reduzir esses riscos.
Esse entendimento é fundamental para qualquer organização que esteja planejando integrar agentes de inteligência artificial em seus processos.
Podcast e Análise Imersiva
Infográfico
Mapa Mental
Estrutura da série
Segurança de agentes de IA na era da inteligência artificial
2️⃣ Artigo 1
Prompt Injection: o novo phishing da era da IA
3️⃣ Artigo 2
Como projetar agentes de IA resistentes a prompt injection
4️⃣ Artigo 3
A superfície de ataque de agentes de IA
5️⃣ Artigo 4
Kill chain de ataques contra agentes de IA
Deixe um comentário